0x00
大概也是去年的这个时候,我写了pixivLocalUpdate,一个Python的小工具,用来实时更新我电脑里庞大的(现在是128GB)pixiv本地图片库。因为文件夹是按作者分类的,比较多,一个一个手动去更新不太现实,就用代码自动去实现。
代码逻辑很简单,就是获取文件目录->获取作者id->检查本地最后一张图片看是否为最新->发现更新并下载。然而问题来了。一开始,我下载是在Python脚本里使用urlretrieve下载,后面为了方便又加了tqdm的进度条,代码如下:
1 | for url in urls: |
但是这个代码经常会在urlretrieve这里卡死,看着进度条在中间就不动了,需要手动停止进程。因为使用urlretrieve下载太慢了,在前几天我重构了代码,调用IDM在更新完所有的文件夹后统一下载。
1 | # IDM为从注册表中获取的IDMan.exe路径(直接传也可以) |
现在不会在下载卡死了,反而会更快的在更新时卡死,频率特别高,很头大。
0x01PySnooper
要知道为什么卡死,那就要首先定位到问题代码,看是在哪里卡死的。使用PyCharm并不方便,因为卡死完全随机,可能更新了30个文件夹才卡死,也有可能更新了1个文件夹就卡死了,很难debug。为了解决这一问题,我使用了pysnooper。
PySnooper https://github.com/cool-RR/PySnooper
Never use print for debugging again
PySnooper is a poor man’s debugger.
You’re trying to figure out why your Python code isn’t doing what you think it should be doing. You’d love to use a full-fledged debugger with breakpoints and watches, but you can’t be bothered to set one up right now.
You want to know which lines are running and which aren’t, and what the values of the local variables are.
Most people would use
pysnooper使用起来很简单,在需要的函数上添加修饰器即可,它会在运行的过程中自动输出每一步的流程,实时debug。
1 |
|
运行Python文件时,在另一个命令窗口里执行tail -f log_idm.log就可以实时滚动查看debug了。
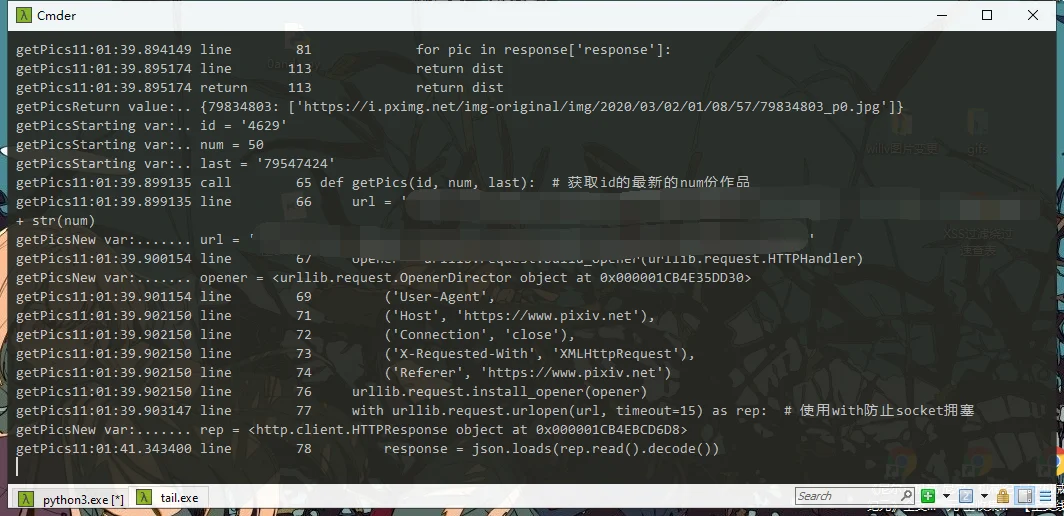
实时调试,每一步都有记录,一旦卡死就能精确定位到代码处。
0x02 timeout
借助PySnooper很容易我们便找到了问题代码:
1 | # 获取某id的最新的作品 |
就这两句,问题都出在了urlopen这里。
为了解决这一问题,我查了很多资料,发现urlopen有一个参数timeout,而我这种问题大概率是因为服务器响应超时,但我代码中没有响应的超时机制而导致的卡死。加上这个参数即可,超时的时间可以自己改。
1 | urlopen(url, timeout=15) # 我这里设置为15s |
这样就没有卡死的问题了,但是一旦超时将会抛出异常。有异常不怕,但是我不想手动的去重试下载,于是就要考虑怎么改代码了。
0x03 retrying
一开始我考虑通过flag来标记超时,再通过循环和判断来重试。但是这样代码修改的又比较多。然后,我又发现一个神器retrying。
1 | from retrying import retry |
一开始百度到这个,但是根据各种教程,CSDN也好,博客园也好,都不对,报错提示没有这个参数。然后我亲自去了pypi的retrying的官方介绍页 https://pypi.org/project/retrying/ 去看看到底是那里出了问题。
然后我发现,百度搜到的那些文章,参数全都是错的!不知道是省略了还是抄的时候丢东西了,官方一长串的参数只写一点点。之后,我又去retrying的GitHub页面( https://github.com/rholder/retrying )看了一下,才把参数定好。因为参数比较多,我这里就不介绍了,可以去pypi或GitHub看。
retrying顾名思义,就是很简单的加上修饰器后,可以根据设置的参数自动重试代码,省去了很多不必要的麻烦。
0x04
至此,代码就基本改完了。以前跑几个文件夹就卡死需要手动重试,现在可以一口气完成更新500多个文件夹,效果拔群,不需要人工介入。


